笔者在深度学习入门期间自学过Transformer,但是那时碍于急于求成,并未对其进行深度归纳与分享。
近期,笔者观察到不论是自然语言处理模型还是视觉模型,已经几乎从传统的CNN、RNN的网络结构设计全面转向基于Transformer的结构设计了。
如下图1所示,在ImageNet数据集上,基于Transformer的网络的精度几乎已经全面领先基于纯CNN设计的网络了。
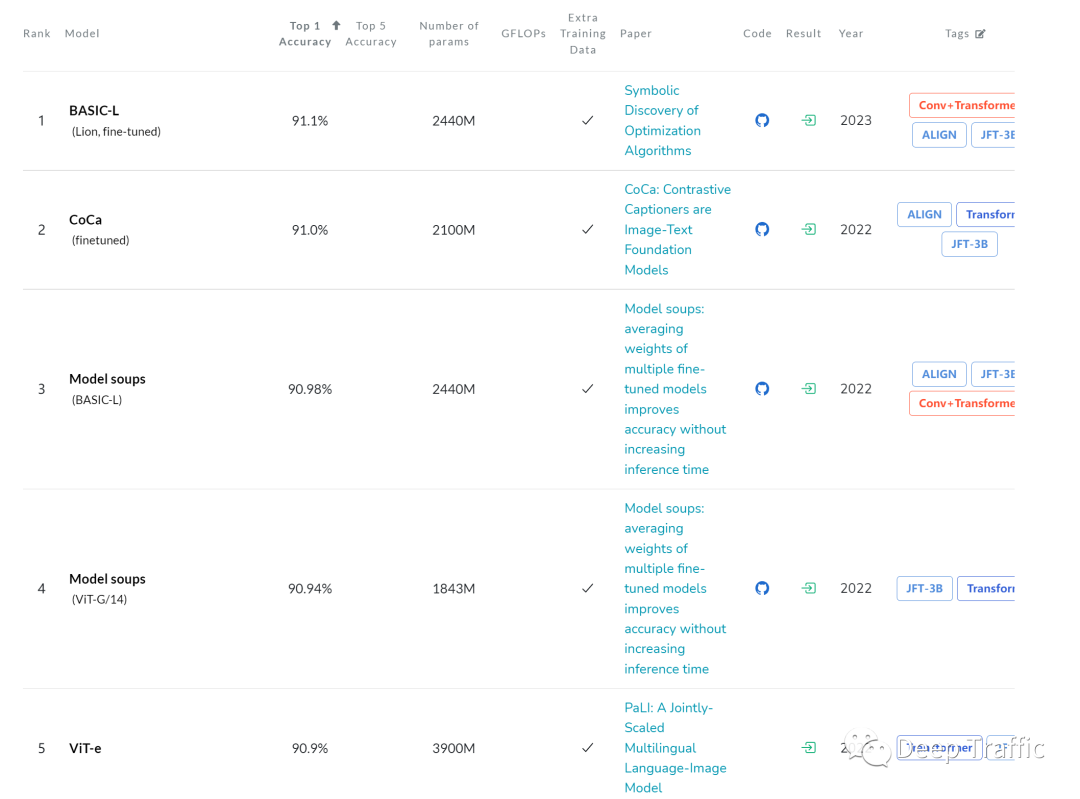 图1
图1
另外,最近大火的chatGPT,其核心也是基于Transformer构建的。这不禁重新燃起了我来做一期对于基础Transformer解析类文章的兴趣,便于新手入门和老手复习。
关于对Transformer的解析,网上已经有很多不错的相关教程了,这里推荐几个笔者认为写的不错的。
“
- 知乎文章《详解Transformer (Attention Is All You Need)》,点赞7000+
- 知乎文章《Transformer模型详解(图解最完整版)》,点赞4000+
- 非常有名的英文教程《The Illustrated Transformer》,知乎文章(1)就是借鉴该教程的
- B站李宏毅视频《第5讲-Transformer-1_哔哩哔哩_bilibili》
- 本文
与现有文章不同的是,本文我们打算结合相关的代码,从理论结合实践的角度加深读者对Transformer的理解。本文采用的代码是:
“
https://github.com/hyunwoongko/transformer
2 提出动机
Transformer提出的具体动机在现有文章中已经被阐明的很清楚了,总结而言就是:
(1)递归神经网络(RNN)或卷积神经网络(CNN)来处理序列数据时,在长序列上的表现不佳,因为它们难以捕捉长期依赖关系;
(2)递归神经网络(RNN),包括LSTM/GRU及其变体,只能从左向右依次计算或者从右向左依次计算,也就是当前时刻的计算依赖上一步计算的输入,严重限制了模型的并行能力;
所以,Transformer另辟蹊径,仅用自注意力(self-Attenion)和前馈网络/全连接层(Feed Forward Neural Network)就作为其主体框架,便获得对输入数据(文本、图像)较好的并行处理能力。另外,自注意力的使用使得模型对较长序列输入的处理能力也大大提升。
3 方法与代码详解
3.1 整体模型预览
本文我们以自顶而下的步骤来逐步解析Transformer中各个模块。为了更好地说明,这里我们借鉴了《The Illustrated Transformer》的原理图,没办法,这位老哥写的太好了,这里强烈建议大家去看一下原版。
假设我们要做一个语言翻译任务,如下图2所示,那么需要构建一个翻译模型,这里不妨这个模型就是基于Transformer构建的。该模型输入一段原始语言(看图片中可能是印度文),输出英文翻译。
 图2
图2
具体地,该基于Transformer构建的翻译模型由两部分构成,分别是编码器(encoder)和解码器(decoder),如下图3所示。
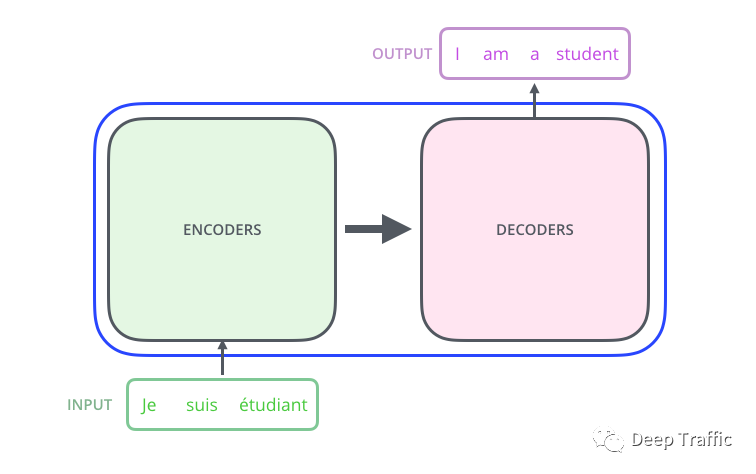 图3
图3
编码器的输出作为解码器的输入。这里的编码器是将输入映射为特征表征(可视为待翻译句子的含义),而解码器根据特征表征实现**“含义—>目标语言”**的转换。具体代码实现如下:
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size, d_model, n_head, max_len,
ffn_hidden, n_layers, drop_prob, device):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.device = device
self.encoder = Encoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
enc_voc_size=enc_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
self.decoder = Decoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
dec_voc_size=dec_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
def forward(self, src, trg):
src_mask = self.make_pad_mask(src, src, self.src_pad_idx, self.src_pad_idx)
src_trg_mask = self.make_pad_mask(trg, src, self.trg_pad_idx, self.src_pad_idx)
trg_mask = self.make_pad_mask(trg, trg, self.trg_pad_idx, self.trg_pad_idx) * \
self.make_no_peak_mask(trg, trg)
enc_src = self.encoder(src, src_mask) # 编码器
output = self.decoder(trg, enc_src, trg_mask, src_trg_mask) # 解码器
return output
从代码的forward函数可以看出,作者先对模型的输入(src,trg)进行了预处理,获取到一些诸如掩码等信息。接着,将这些先喂给编码器(self.encoder)来获取特征表征(enc_src),该特征表征和一些掩码被馈入解码器(self.decoder)中,输出张量翻译信息(output)。
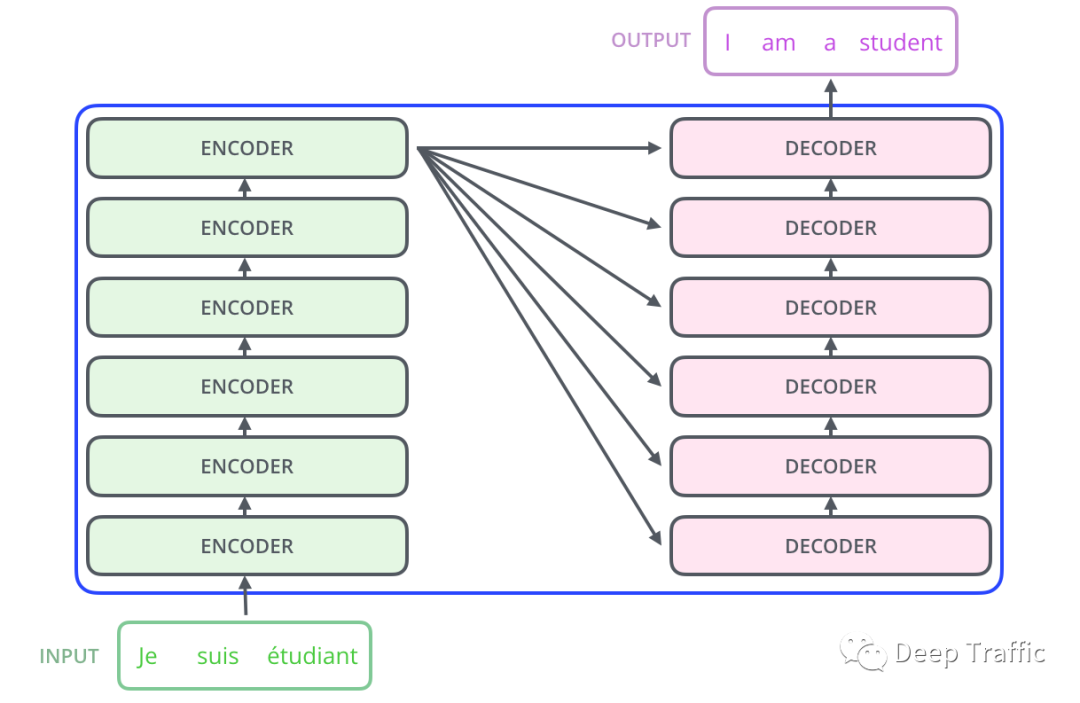 图4
图4
如上图4所示,这个编码器和解码器的结构可以总结如下:
(1)编码器
编码器由一个嵌入层+六个编码层构成,每个编码层由一个自注意力(self-Attenion)和一层前馈网络(Feed Forward Neural Network)组成,如下图5所示。需要注意的是,自注意力和前馈网络中均包含残差连接(目的是为了防止梯度消失,提高训练稳定性);
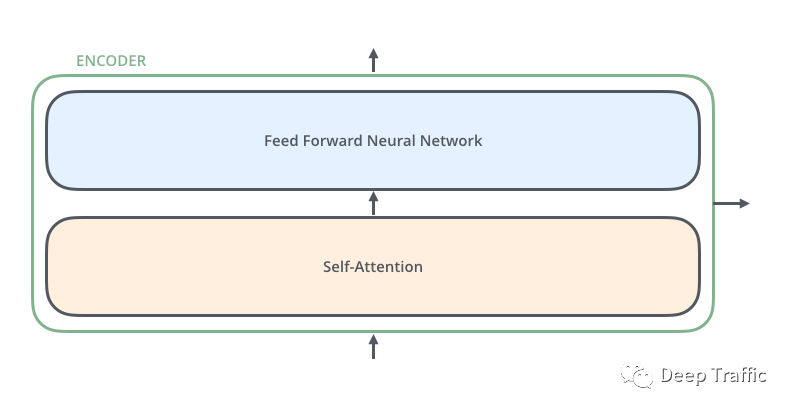 图5
图5
编码器的代码实现如下所示:
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, s_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, s_mask)
return x
上述代码中的self.emb就是嵌入层,n_layers被设定为6,表示该编码器由6层解码层(EncoderLayer)构成。我们再进入EncoderLayer的定义,可见:
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, s_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=s_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
通过查看上述代码的forward函数,可见在每个编码层中执行了如下操作:
- (1)自注意力操作( self.attention)
- (2)相加和归一化(也就是残差连接)
- (3)前馈网络运算(self.ffn,本质就是全连接层)
- (4)相加和归一化(残差连接)
(2)解码器
解码器由一个嵌入层+六个解码层+一个输出层构成,每个解码层由一个自注意力(self-Attenion),一个编码-解码注意力(Encoder- decoder Attention)和一层前馈网络(Feed Forward Neural Network)组成,如下图6所示;
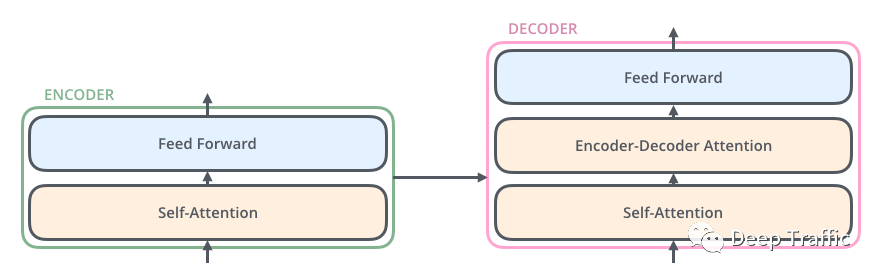 图6
图6
解码器的代码实现如下所示:
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, enc_src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, enc_src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output
其中,self.emb为嵌入层;n_layers=6,这表明解码器由6个解码层(DecoderLayer)构成;最后,使用输出层(self.linear)将解码特征映射为字向量输出。这里,我们就解码层(DecoderLayer)展开,其具体实现代码如下:
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head) self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, t_mask, s_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=t_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=s_mask)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.dropout3(x)
x = self.norm3(x + _x)
return x
从上述代码可以看出,每个解码层比编码层多了一个模块运算,即编码-解码注意力及其残差连接。
再仔细一看,这个编码-解码注意力的k和v值为enc,其实也就是编码器的输出。也就是说,每层解码层的输入不光有上一解码层的输出(dec),还有编码器的最终输出(enc),和图4中展示的一致。
写到这里,Transformer的大致结构大家应该就有了初步的印象了。这里需要提一嘴的是,编码-解码注意力(Encoder- decoder Attention)的本质也是个自注意力,其唯一区别仅在输入的来源上。而前馈网络(Feed Forward Neural Network)其实就是全连接层与激活函数的组合,并不需要进行重点解析。
那么这样一来,我们只需要理解自注意力的具体实现,也就掌握了Transformer的核心了。
3.2 自注意力
自注意力模块,笔者最先接触的时候是在做视觉任务遇到了一个叫做Non-local注意力模块,其结构如下图7所示(具体见我之前写的知乎文章)。事实上,该模块就是借鉴自注意力进行设计的。
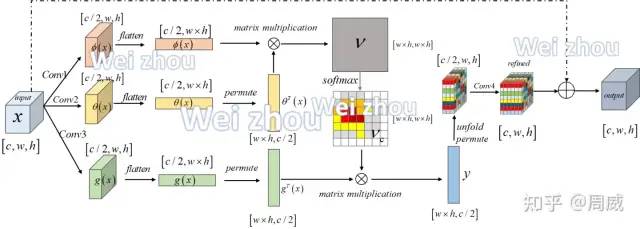 图7
图7
在Transformer中,每个单词向量(embeddings)被映射成三个不同的向量,分别叫做Query向量(Q)、Key向量(K)和Value向量(V),如下图8所示。具体是怎么个映射法呢,就是输入到三个不同的全连接层(内参分别为、和)中即可。
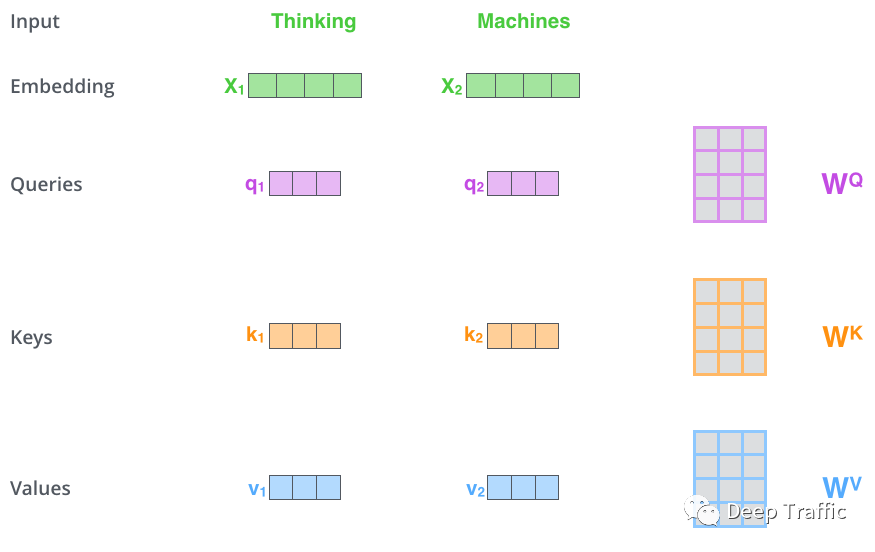 图8
图8
在每个单词向量都获取了其对应的三个Q、K、V向量后。对于任意单词,用它的Query向量(Q)去探索自身和其他单词的Key向量(K),如下图9所示。具体探索方法就是两者进行点积,某种意义上就是求解余弦相似度,如果两者相似度较高,则赋予较大的值(下图中的Score)来反应两者的关系。
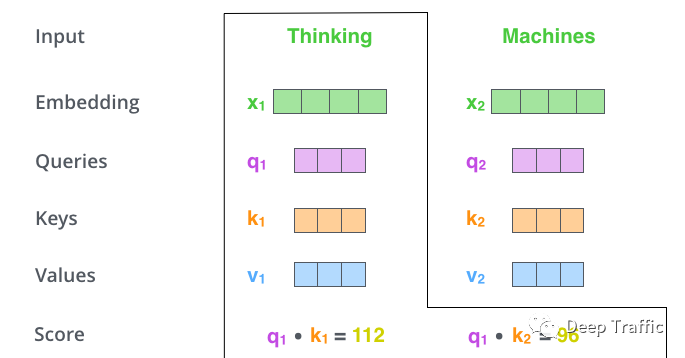 图9
图9
上述计算可以大致把握两个单词之间的相似度(或者称为关联性,即图中的Score)。之后,需要利用该相似度来衡量各单词相对于所关注单词(上图9中受关注的单词为thinking)的重要性,进而对各个单词所占权重进行调整。
具体地,作者先是对每个计算的相似度进行了标准化,然后使用softmax函数将标准化的相似度转换成了注意力,如下图10所示。
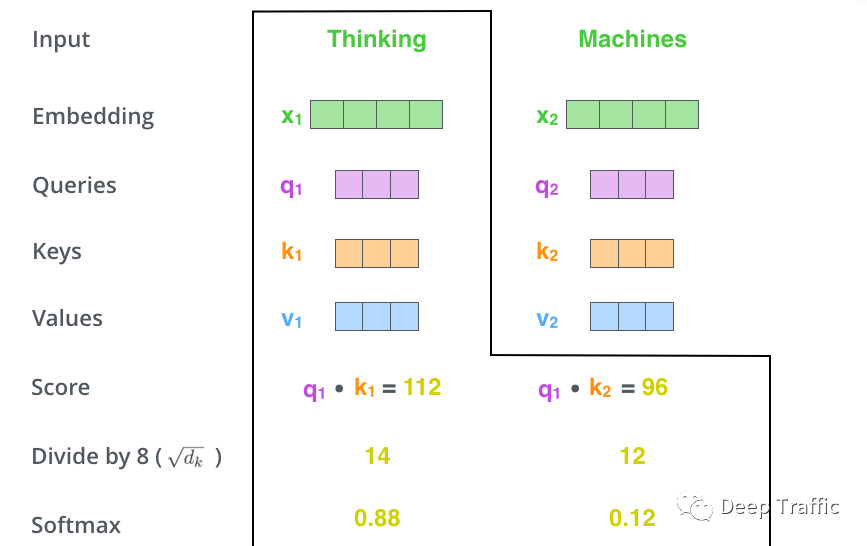 图10
图10
接着,如图11所示,作者利用获取的注意力来调整各单词Value向量(V)所占的权重。最后,对加权后的各单词Value向量(V)进行按位相加融合,获取自注意力模块的输出(就是图10中的)。
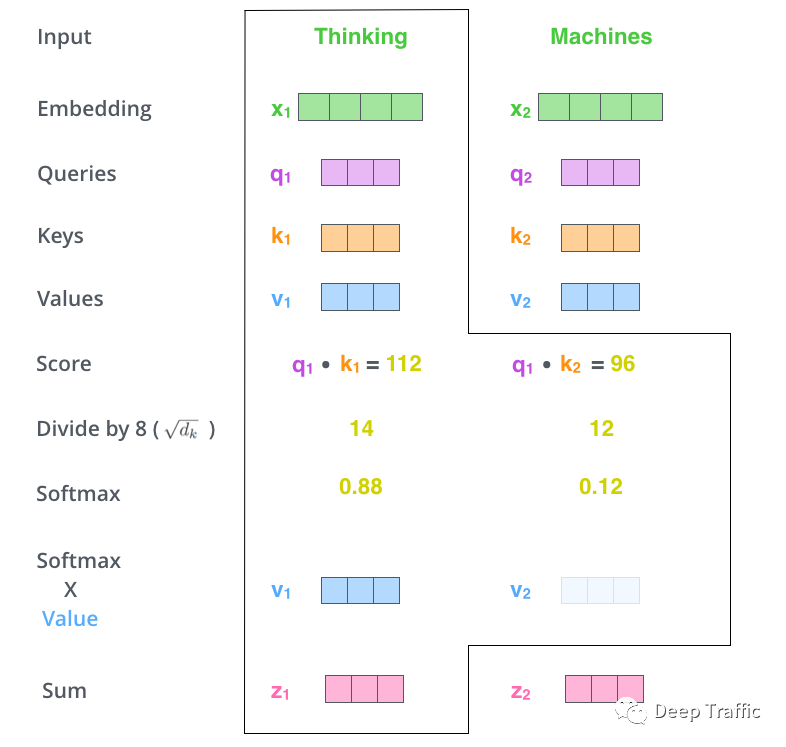 图11
图11
为了便于大家理解,上面的讲解是拆分进行的。在实际计算过程中,采用了基于矩阵的计算方法来提升运算效率,具体如下图12所示。
假设有2个单词,每个单词维度为4(当然这只是假设),那么输入的维度就是。然后通过三个不同权重的全连接层(权重维度为)将输入映射为三个维度为的向量,即Query向量(Q)、Key向量(K)和Value向量(V)。
那么上述关于自注意力的运算步骤可以用下面公式表示,即
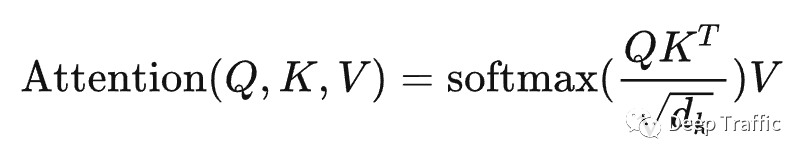
更形象地,其图示为:
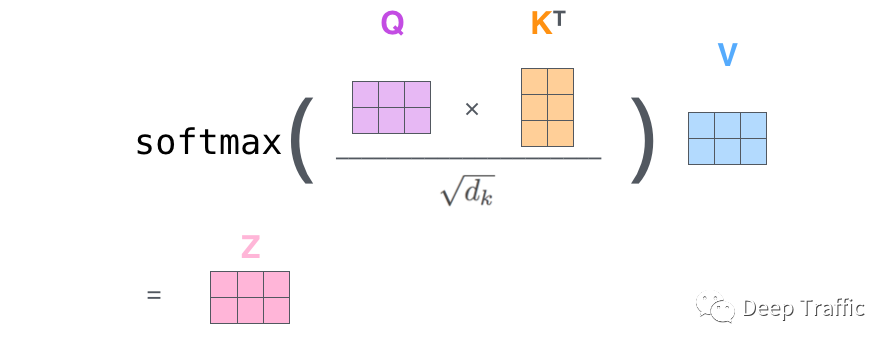 图12
图12
其代码实现如下所示:
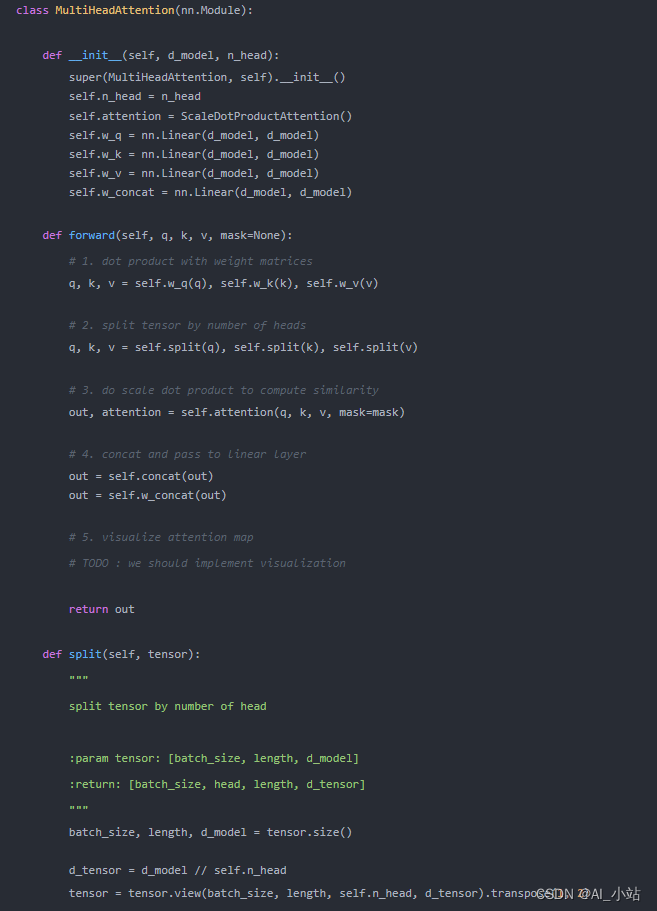
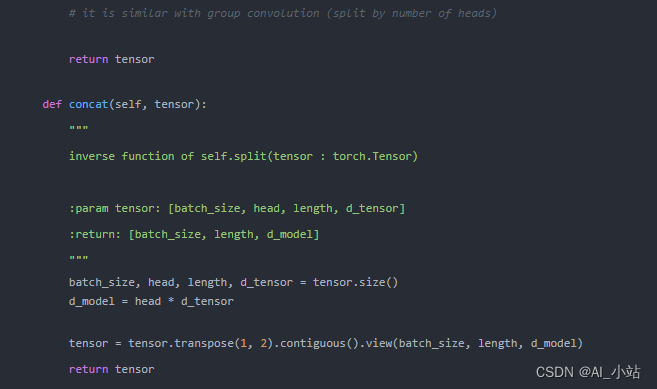
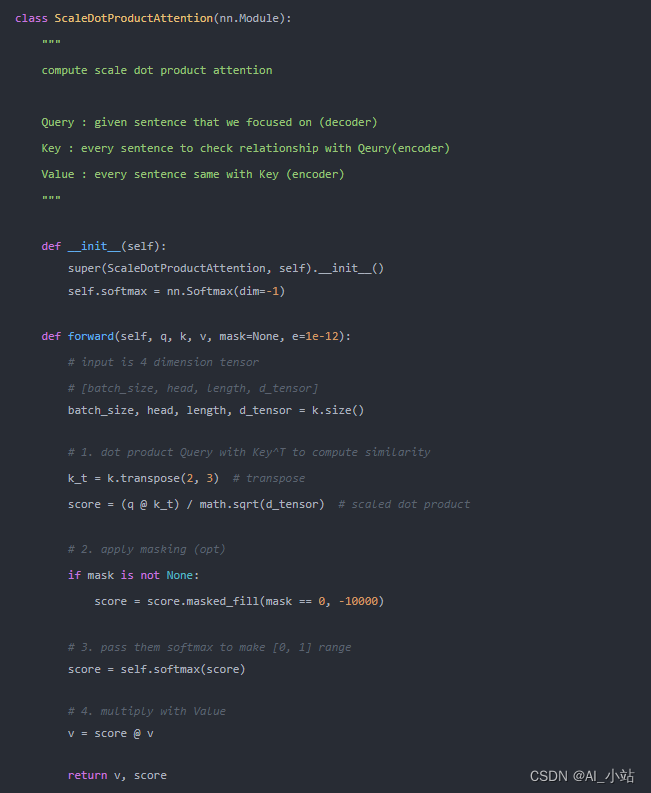
其中self.attention(自注意力)定义为:
需要注意的是,上面文字部分我们讲了那么多,其实是在讲解单头自注意力。然而,细心的小伙伴应该发现了上述代码定义的是多头自注意力。我们可以认为,当self.n_head=1时,就是上面我们讲解的单头自注意力了。当然,在Transformer中,作者默认采用的是多头自注意力,这是为什么呢?
因为,相比单头自注意力,多头的优势主要体现在:
- 更好的建模能力:利用多个注意力头可以捕获序列中更多的信息和特征,从而提升模型的建模能力。
- 更好的泛化能力:多头自注意力可以提高模型对新数据的泛化能力,因为它可以将不同方面的特征编码到不同的注意力头中,从而使模型更加全面地理解输入序列。那么多头是如何实现的呢?
如图13所示,假设self.n_head=8,即八头注意力,对于每个头(序号为)都执行一次单头注意力运算,获得相应的输出。最后,对所有头所处的进行堆叠融合后,利用全连接层将其映射成与单一注意力输出相同的尺寸即可。
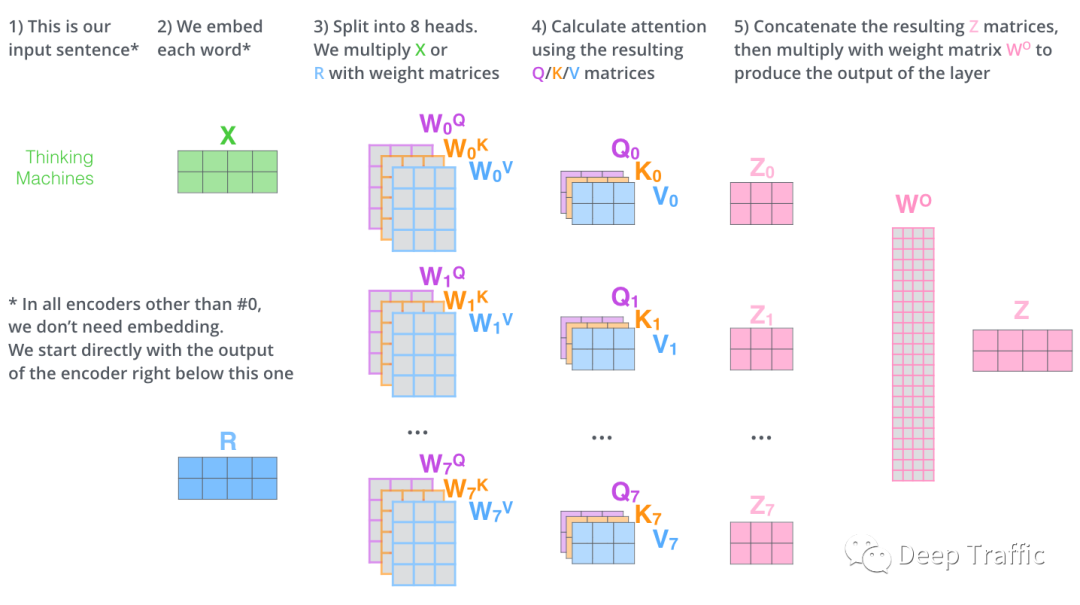 图13
图13
至此,关于Transformer的核心部分(即自注意力)就讲解完毕了。这里顺嘴提一下,从上述代码中可以看出,解码层中的编码-解码注意力(self.enc_dec_attention)的定义也是一个多头自注意力(MultiHeadAttention类),唯一区别在于其输入的Query向量(q)为前面解码器的输出(x),而Key向量(k)和Value向量(v)输入为编码器的输出(enc)。
下面我们就Transformer另外两个重要的创新进行解析,分别为:
- 位置编码
- 输入掩码
3.3 位置编码
从上面的解析可以看出,自注意力对输入序列中各单词的位置/顺序不敏感,因为通过Query向量和Key向量的交互,每个单词的距离被缩小为一个常量。这样会导致一个很严重的问题,比如“我吃牛肉”这句话,在Transformer看来和“牛吃我肉”是没什么区别的。
为了缓解该问题,作者提出了位置编码。简而言之,就是在词向量输入到注意力模块之前,与该词向量等长的位置向量进行了按位相加,进而赋予了词向量相应的位置信息。
那么,如何获取该位置编码呢?作者给出了位置编码的定义公式,具体如下:
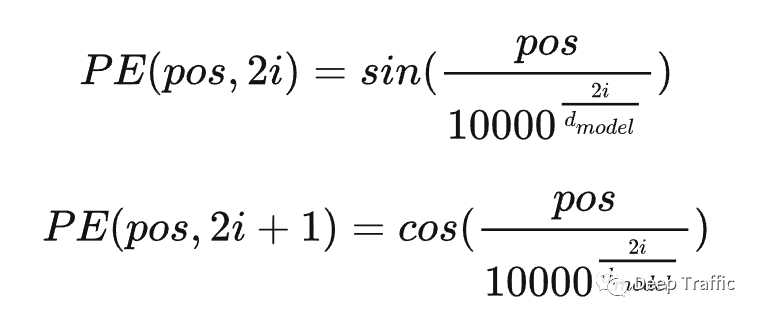
乍一看,变量有三,公式还有两个,着实不太好懂。这里需要注意,为位置向量的维度,前面提到该维度与词向量维度一致。变量为单词在句子中的位置,比如“我吃牛肉”,那么这个牛的。那么这个又是什么东西呢?其实,这个和分别表示位置向量的偶数位置和奇数位置,自然而然地,。
作者这样定义位置编码的原因在于:
- 使得Transformer可以更容易掌握单词间的相对位置,因为Sin(A+B)=Sin(A)Cos(B)+ Cos(A)Sin(B), Cos(A+B)= Cos(A)Cos(B)- Sin(A)Sin(B)。那么知道某单词的位置编码后(如),其相对距离为的单词的位置编码()可以根据函数和函数的性质快速计算出。
- 即使在测试的时候遇到比训练集中所有句子都长的句子,上述公式也可以给出一个合适的位置编码。
位置代码获取的代码实现如下:
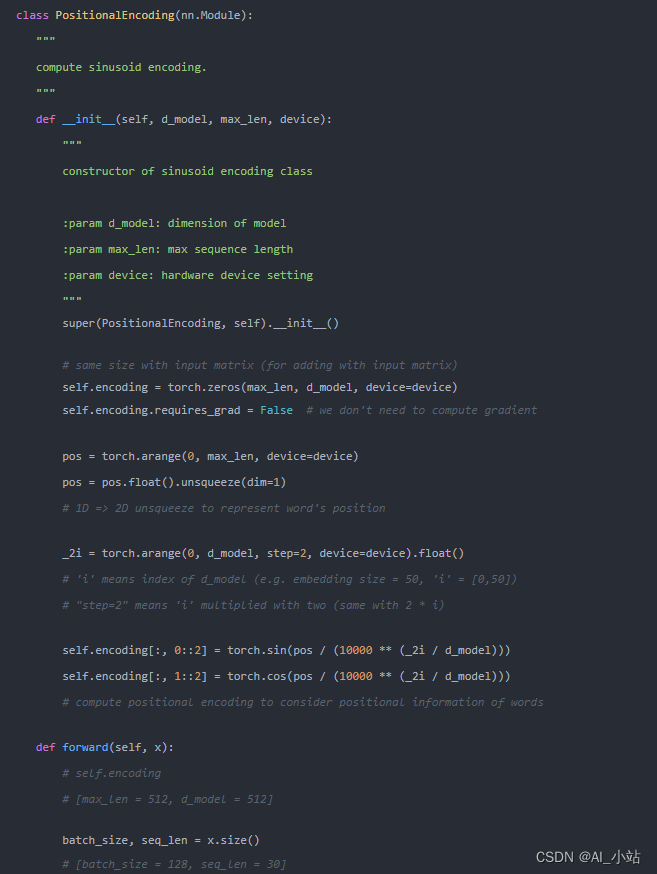

这里也提供一个图例加深读者理解,如图14所示。图中每一行对应于一个词向量的位置编码,可见该句子共有20个词(0-19),其中第一行是输入序列中第一个单词向量的位置编码。每一行包含512个值(即),每个值都是按照上述计算公式计算而来,介于1和 -1之间。左半部分的值由正弦函数计算获得,而右半部分的值由余弦函数计算获得。在实现中,将这两部分计算出来的值穿插拼接起来,就可以形成每个单词对应的位置编码了。
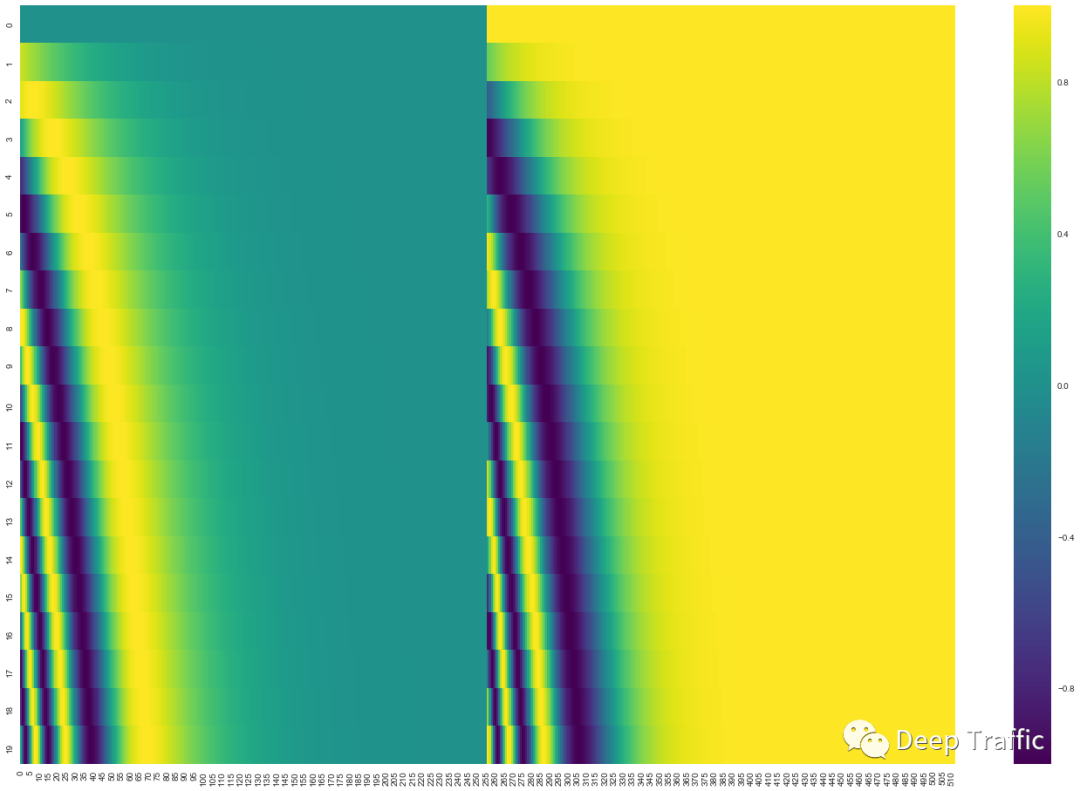 图14
图14
至此,关于位置编码的解析就结束了,相信大家在仔细看完上述解释和代码后,应当能够理解位置编码的含义了。
3.4 输入掩码
输入掩码是笔者认为比较重要的一部分了。在深度学习中,掩码的作用一般是让模型自动忽略一些内容。
正常的翻译逻辑应该是,模型在接收原始语言的语句输入后(利用编码器进行编码),会利用解码器一个词一个词地逐个翻译。也就是,时刻翻译的单词会考虑之前时刻(如,)已经翻译好的所有单词。在Transformer的测试阶段,这是这样执行的。
那么可能会有人会问,前面不是提到Transformer的一大亮点在于其并行能力吗?这不还是在等待前面翻译的内容作为后续的输入吗?
这里需要解释一下,这种情况只发生在测试阶段。在训练阶段,作者利用将监督信息(即目标翻译)右移一位作为解码器的输入(加上了一个起始符),并设置掩码使得解码器在时刻的翻译只能考虑输入目标翻译时刻之前(如,)的内容,这是为了防止翻译信息的提前泄露。如图15所示,我举了个例子,
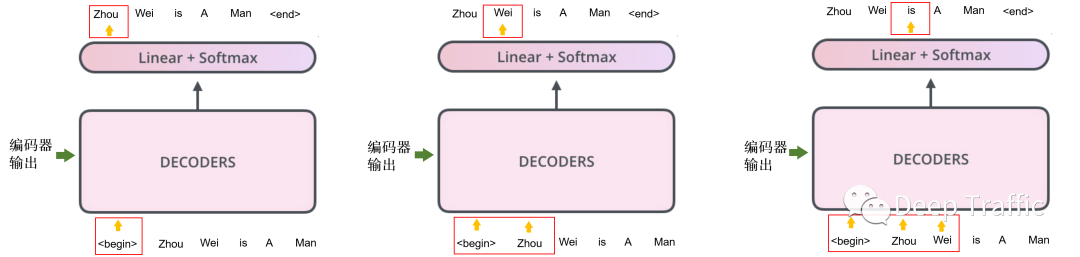 图15
图15
从上图15可以看到,翻译第个单词时,都会用到目标翻译第1个到第个单词作为输入。需要注意的是,这里的训练方式叫做Teacher Forcing,也就是不管你模型最后的输出是啥,你的输入都得是目标翻译的一部分,给你强行扭过来。当然,在测试/应用阶段,解码器前一时刻的输出将作为后面的输入,因为我们是无法在测试阶段提前获取目标翻译的。
为了实现这种“翻译第个单词时用到目标翻译第1个到第个单词作为输入”,作者引入了输入掩码,具体实现也很简单。这里借鉴《知乎文章:Transformer模型详解(图解最完整版)》的图来更好的说明,具体如下:
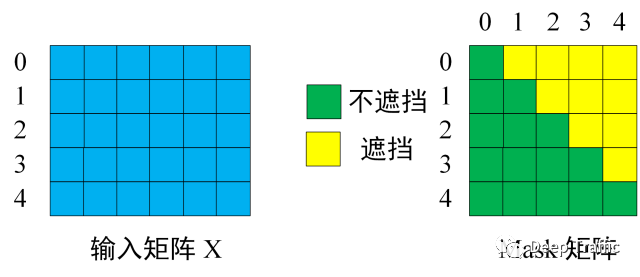 图16
图16
假设输入到Transformer解码器的矩阵维度为(也就是包含在内有5个单词,每个单词视作6维度),那么在翻译第一个单词时,只会用到起始符,而翻译第二个单词时只会用到起始符和第一个单词,后续类推,那么设置的掩码矩阵应该如上图16右边的Mask矩阵所示。
该Mask矩阵用在哪儿呢?这里通过查看自注意力的代码实现,如下:
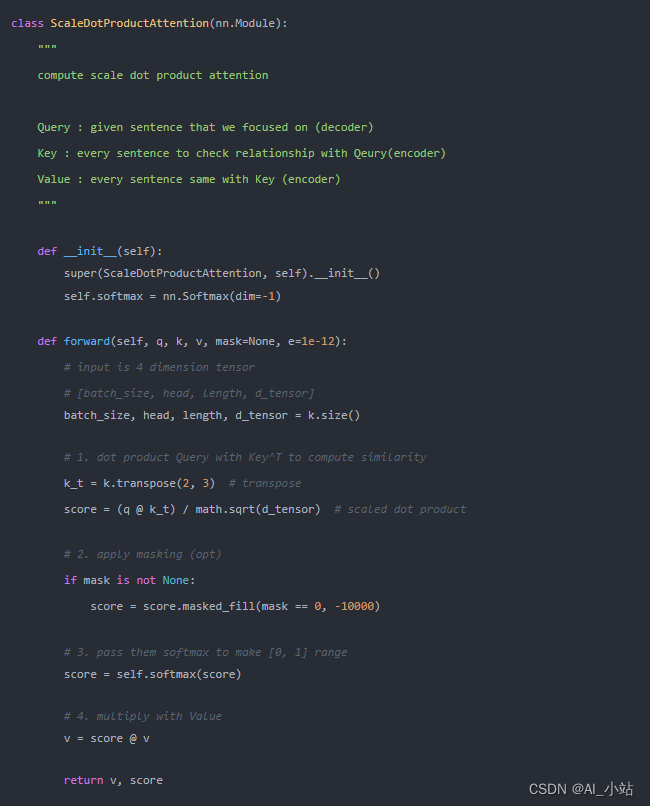
可以发现,Mask 操作是在自注意力模块计算Score后,以及使用 Softmax 之前使用的。
4 总结
写到这里,关于Transformer比较重要的点基本都讲解完毕了。如果大家一路看过来,能够理解我的所言所语,我相信应该会有所收获的。本期内容还是侧重于对基础Transformer的讲解,未来我打算多去分享一些基于Transformer设计的网络模型以及实际应用。欢迎大家关注!
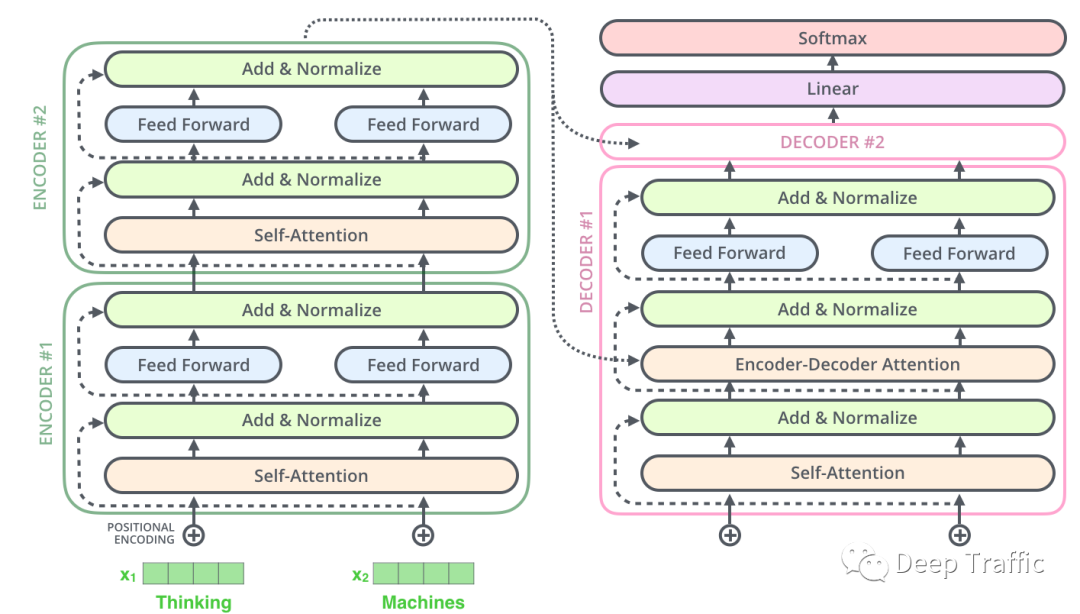 图17 Transformer总结构图
图17 Transformer总结构图
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。



![[图解]分析模式高阶+课程讲解03物品模式](https://img-blog.csdnimg.cn/direct/b0960148e0c8448c91ca5265137ae2df.png)